Analyzing the Sentiment & Modeling Topics for the UN General Debate Corpus
(with bibliography)Introduction
The United Nations (UN) stands as a pivotal international organization, tasked with promoting peace, upholding international law, and fostering global socio-economic progress. The annual General Debate (GD) of the United Nations General Assembly (UNGA) serves as a crucial forum for member states to address pressing issues and outline their priorities. These speeches, delivered by heads of state or government, provide valuable insights into each nation's stance on global affairs.
The United Nations General Debate Corpus (UNGDC), compiled by Jankin Mikhaylov et al. (2019), offers a comprehensive collection of these speeches in English from 1970 to 2018. In this study, I analyze this corpus to explore variations in sentiment across countries and over time. Building on prior research by Baturo & Dasandi (2017), I focus specifically on the speeches of the P5 member nations: the United States, Russia, the United Kingdom, China, and France.
Following an overview of the dataset and preprocessing steps, I employ sentiment analysis to assess the overall tone of the speeches. Additionally, I utilize structured topic modeling techniques to identify distinct themes discussed by the P5 nations. These analyses reveal prevalent topics such as millennium development goals and the principle of self-determination.
Furthermore, I propose a classification model to differentiate between speeches of the P5 member nations based on their linguistic characteristics. By examining the choice of words used in these speeches, we gain insights into the diplomatic priorities and communication strategies of these influential countries.
In summary, this study offers a comprehensive analysis of the United Nations General Debate, shedding light on sentiment trends, thematic focuses, and linguistic patterns among member nations, particularly the P5. Through these insights, we deepen our understanding of international discourse and diplomatic dynamics within the UN.
The Data
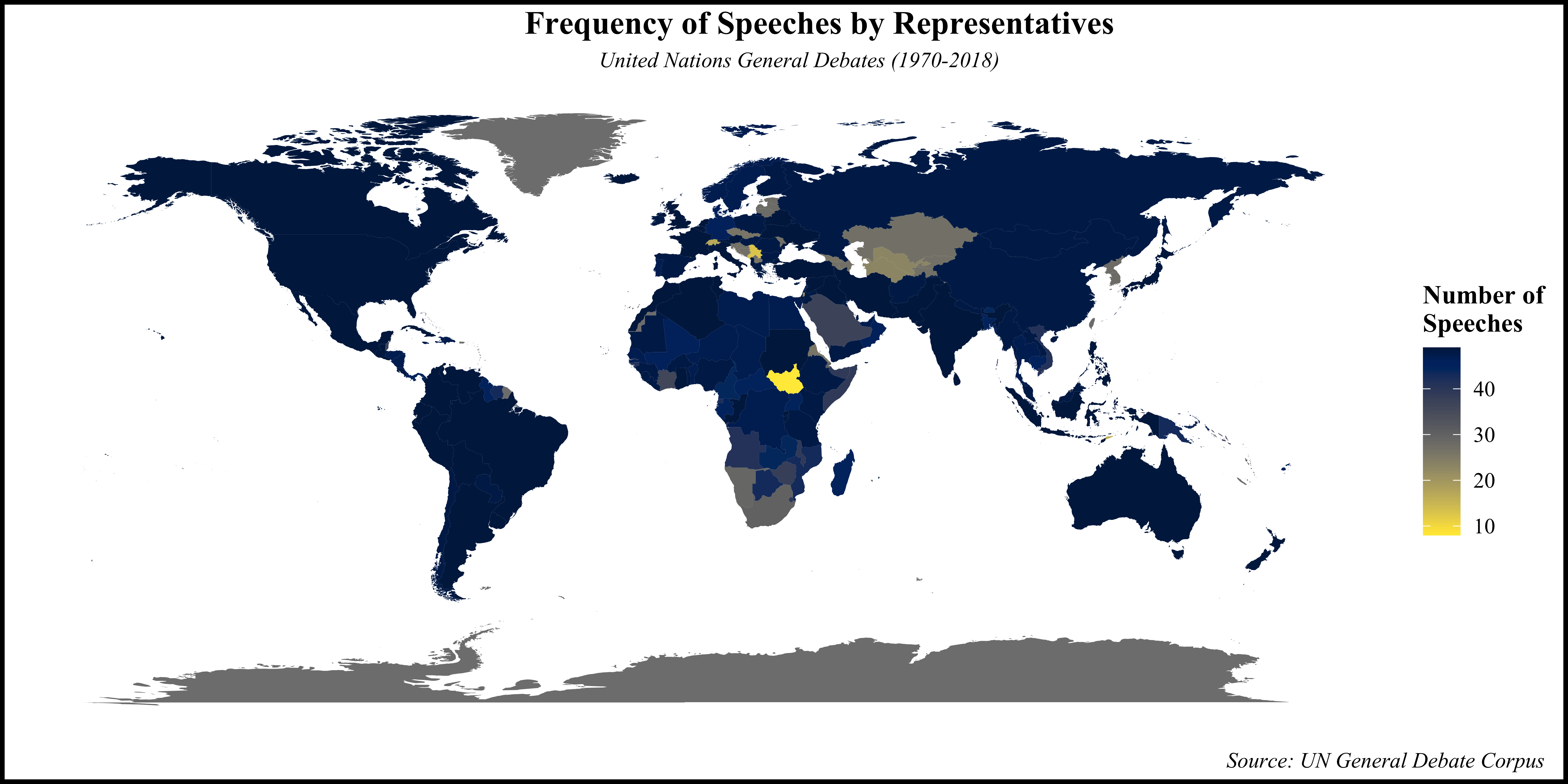
The United Nations General Debate Corpus (UNGDC) encompasses speeches delivered by representatives from 200 member nations at the General Debate sessions of the United Nations General Assembly (UNGA) spanning from 1970 to 2018, all presented in English. Figure 1 illustrates the distribution of speeches by country, revealing variations in participation over time. The dataset comprises 8,093 observations, each corresponding to a country-year pair.

Table 1 displays a sample of the dataset, featuring columns such as 'doc_id' (file name), 'text' (speech content), 'Country' (ISO 3-letter country code), 'Session' (UNGA session), and 'Year' (year of session). Notably, 'Country' is treated as a categorical variable, while 'Session' and 'Year' are continuous variables.
Preprocessing
In preprocessing the text data from the UNGDC, a bag-of-words approach is utilized, representing each document with a set of words and phrases up to 4-grams, without considering grammar or word order. Tokenization is performed using a simple approach, as shown in Figures 2(a) and 2(b), where both methods yield similar results. Punctuation, symbols, numbers, and URLs are removed, and tokens are converted into up to 4-gram tokens.
Subsequently, the tokens are transformed into a document term matrix by lowercasing all letters and removing separators, with the removal of stop words to address issues encountered in previous analyses with the dataset. Lemmatization is then applied using the lexicon hash lemma. The resulting document term matrix includes only the P5 nations, comprising 243 documents with 508,877 features and 99.33% sparsity.
To optimize the matrix, a minimum document frequency of 20 and a maximum document frequency of 170 are applied, resulting in a sparse matrix with 2,640 features and 77.58% sparsity. The minimum row sum value is 287, with a median of 958 and a mean of 1,062.
Sentiment Differences Across Nations & Years
The sentiment analysis was conducted using the Lexicoder Sentiment Dictionary (Young & Soroka, 2012) in R. Initially, the overall positive and negative sentiments were calculated by summing the 'negative & neg_positive' columns for negative sentiment and the 'positive & neg_negative' columns for positive sentiment. Subsequently, an average sentiment was computed by subtracting negative sentiment from positive sentiment, aggregated at both country and year levels.
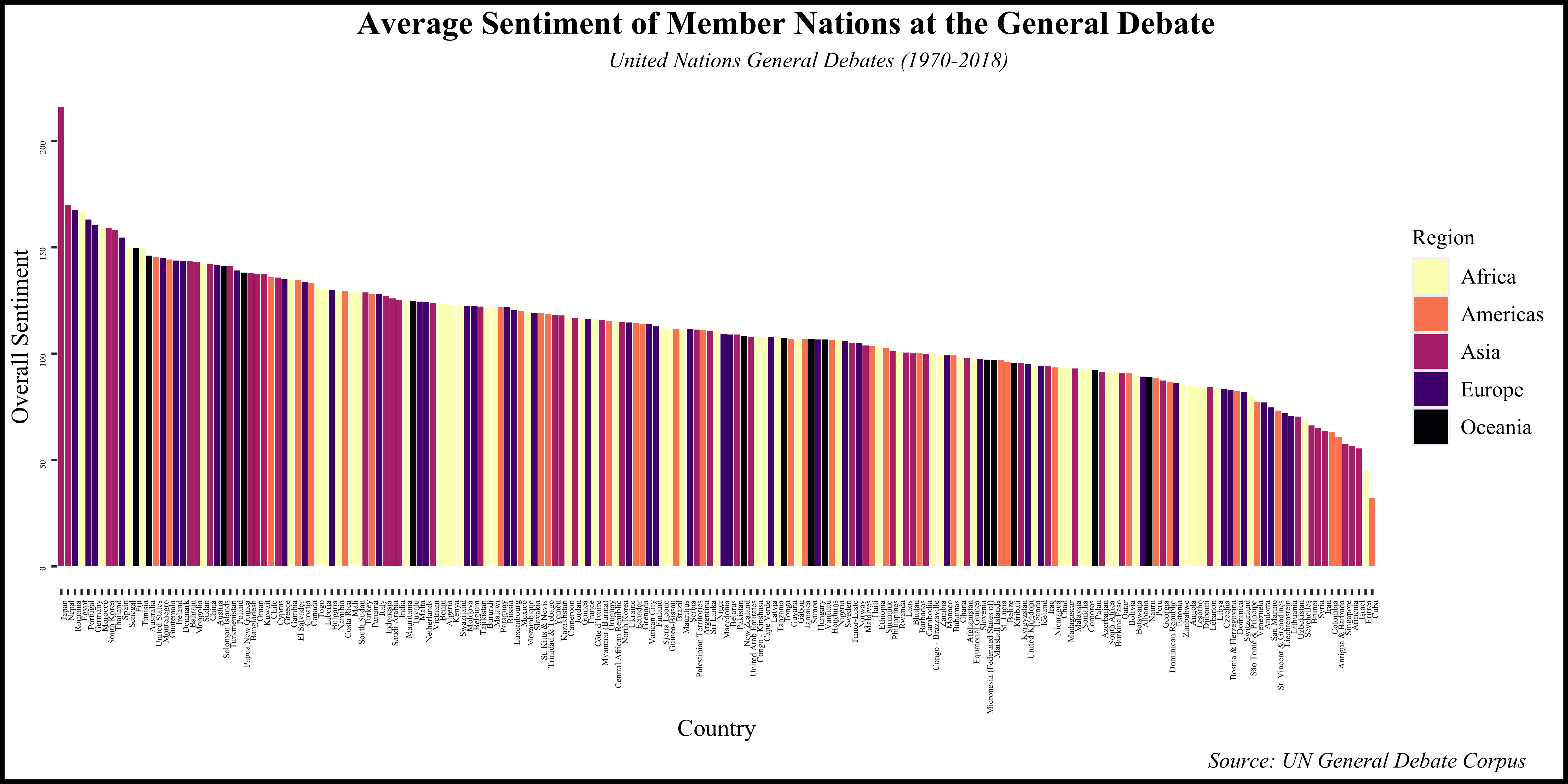
Figure 3(a) illustrates the overall sentiment of countries categorized by regions, revealing a predominance of positive sentiment across the General Debate (GD) sessions. Notably, Japan exhibits consistently positive sentiment over the years, followed by Nepal, Romania, and Egypt. Among the P5 member nations, the United States displays the highest aggregate positive sentiment. Conversely, countries such as Israel, Eritrea, and Cuba express lower positive sentiments over the years.
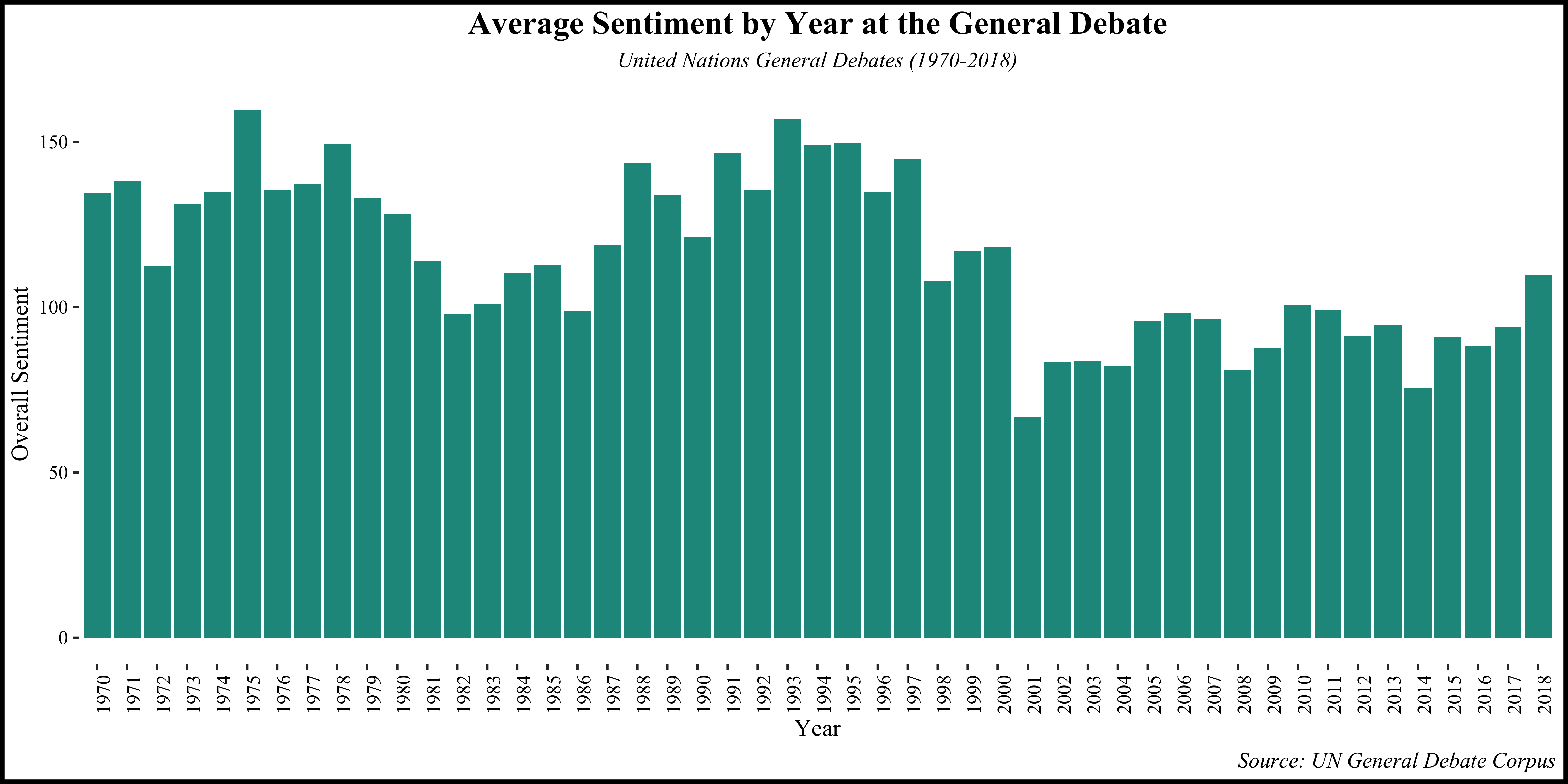
Figure 3(b) depicts the sentiment variation across GD sessions. The most positive sentiment is observed in 1975, whereas the lowest positive sentiment occurs in 2001, shortly after the 9/11 attacks. Despite fluctuations, an overall positive sentiment prevails throughout the UN General Debate, indicating a positive atmosphere within the international community.
Structured Topic Modeling for P5 Member States

The structured topic modeling, following the approach outlined by Baturo & Dasandi (2017), resulted in a 16-topic model, each representing distinct thematic areas discussed by the P5 member nations—United States, Russia, China, France, and the United Kingdom—during the United Nations General Debate sessions.
Topic 1 focuses on Economic Development, with discussions revolving around global trade, privatization, and economic growth initiatives.
Topic 2 centers on Millennium Development Goals, addressing strategies for stability, international crime, and drug trafficking, among other development priorities.
Topic 3 pertains to Europe, covering issues such as regional cooperation, racism, and historical conflicts.
Topic 4 explores Weapons of Mass Destruction, including concerns about proliferation, disarmament, and regional tensions.
Topic 5 addresses Post-World War Rebuilding efforts, reflecting on past mistakes, coexistence, and global peace initiatives.
Topic 6 discusses International Peace & Security, encompassing peacekeeping operations, arms control, and regional conflicts.
Topic 7 relates to the Cold War era, addressing ideological conflicts, nuclear warfare, and non-interference principles.
Topic 8 focuses on Peacekeeping Operations, highlighting United Nations peacekeeping efforts and consensus-building.
Topic 9 examines Terrorism, discussing counterterrorism measures, attacks, and global security threats.
Topic 10 centers on Self-Determination, covering the struggles for independence and sovereignty in various regions.
Topic 11 explores Developing Economies, addressing issues such as industrialization, poverty alleviation, and economic disparities.
Topic 12 pertains to the Middle East & Northern Africa, discussing regional conflicts, Arab-Israeli relations, and humanitarian crises.
Topic 13 delves into Al-Qaeda and related terrorist organizations, addressing their activities and global implications.
Topic 14 discusses Decolonization efforts, reflecting on post-colonial challenges, international cooperation, and regional stability.
Topic 15 focuses on Post-Conflict Development, addressing reconstruction efforts, peace processes, and sustainable development initiatives.
Topic 16 centers on Sustainable Development, discussing climate change, infrastructure development, and global cooperation for sustainability.
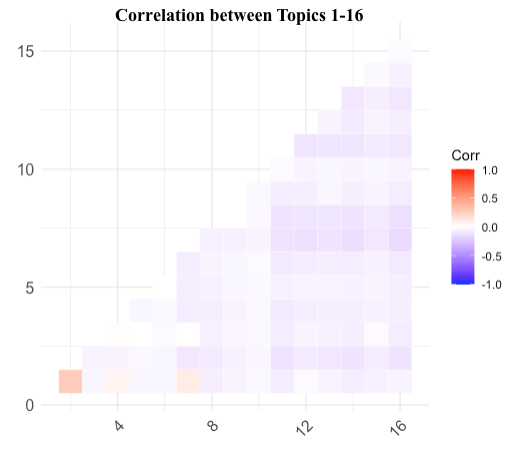
These topics offer a comprehensive view of the diverse range of issues addressed by the P5 member nations in their speeches at the United Nations General Debate sessions. Furthermore, the analysis reveals notable differences in topic prevalence among the P5 countries, with each nation emphasizing certain topics more than others.
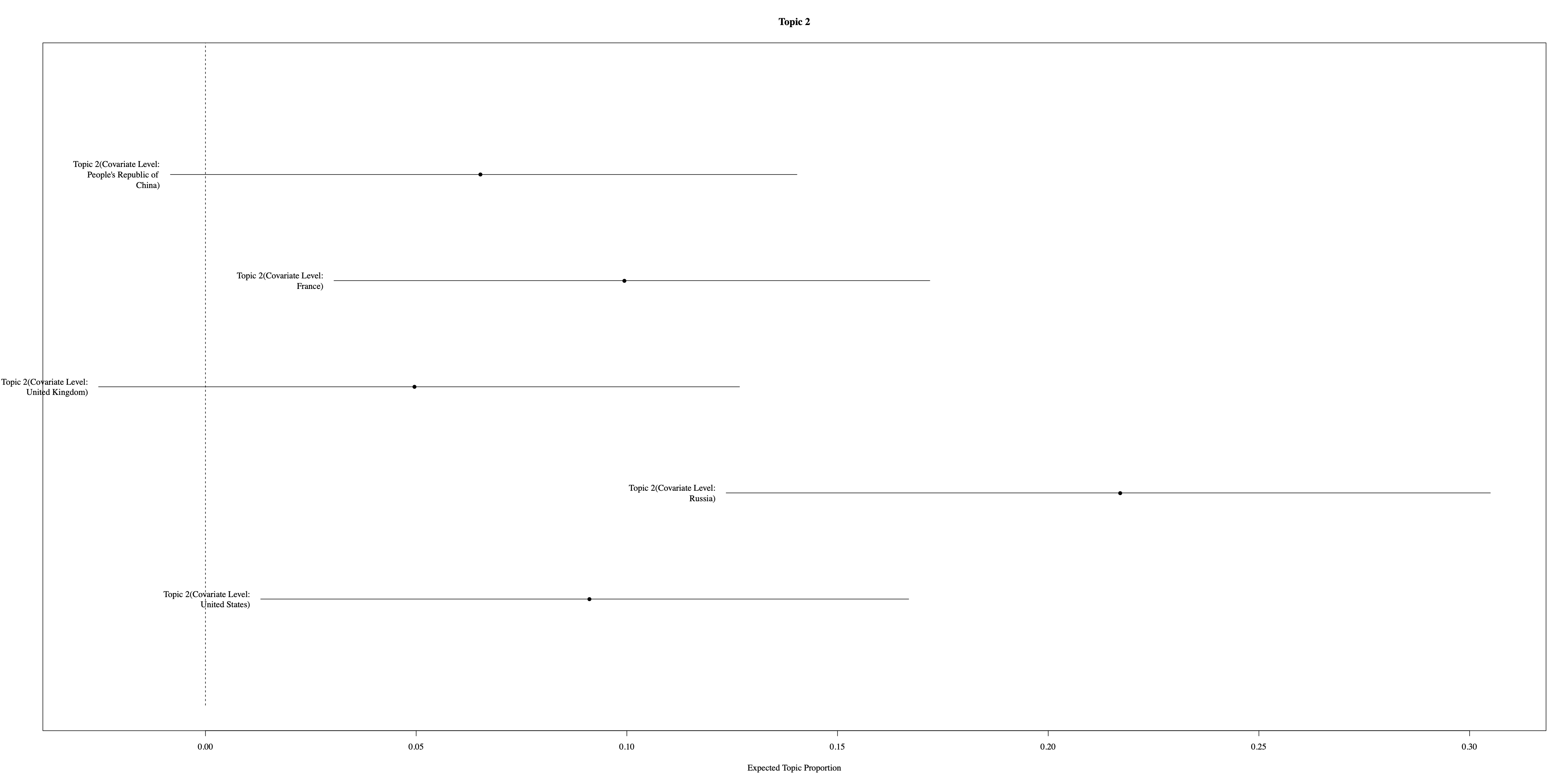
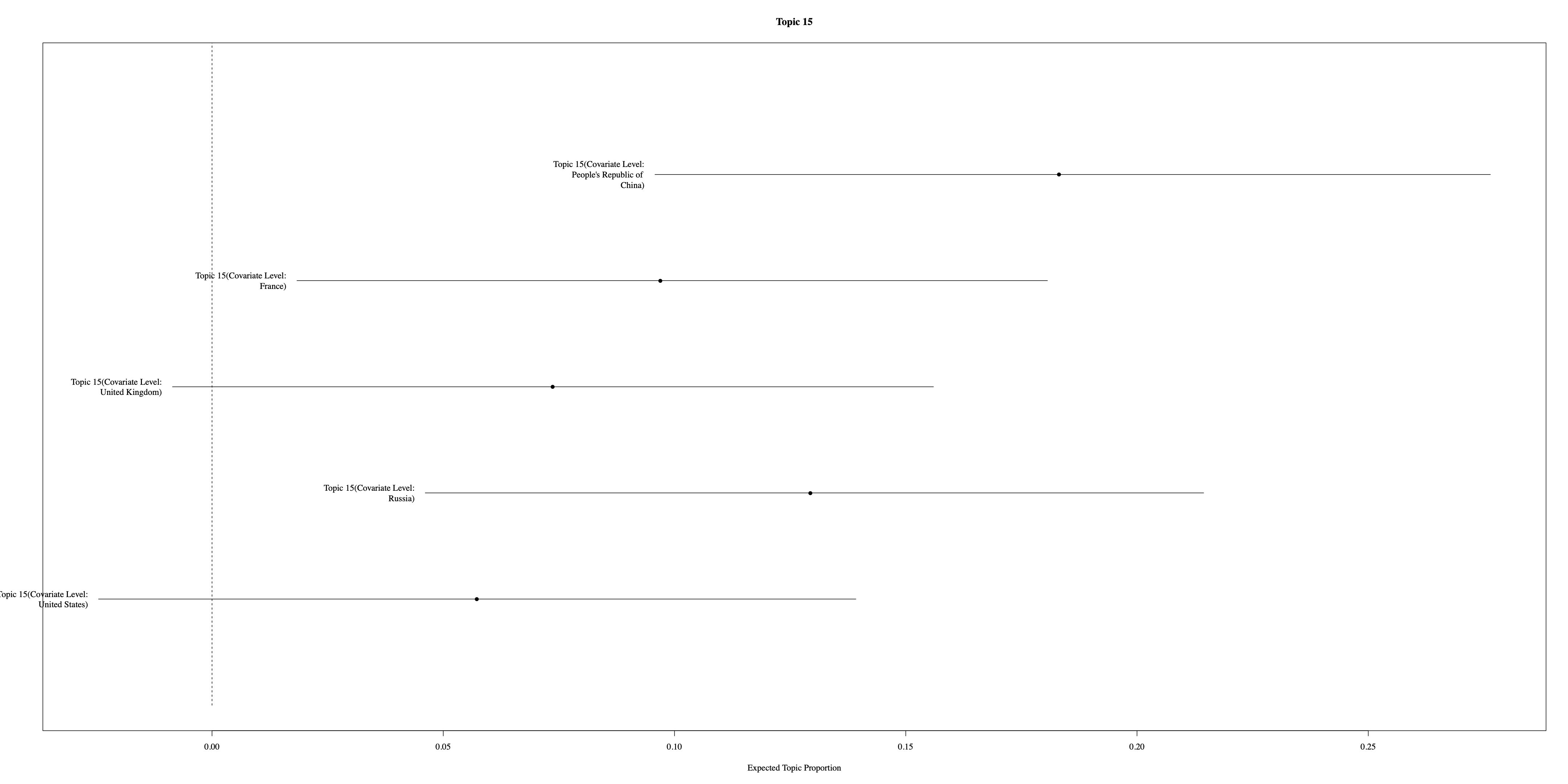
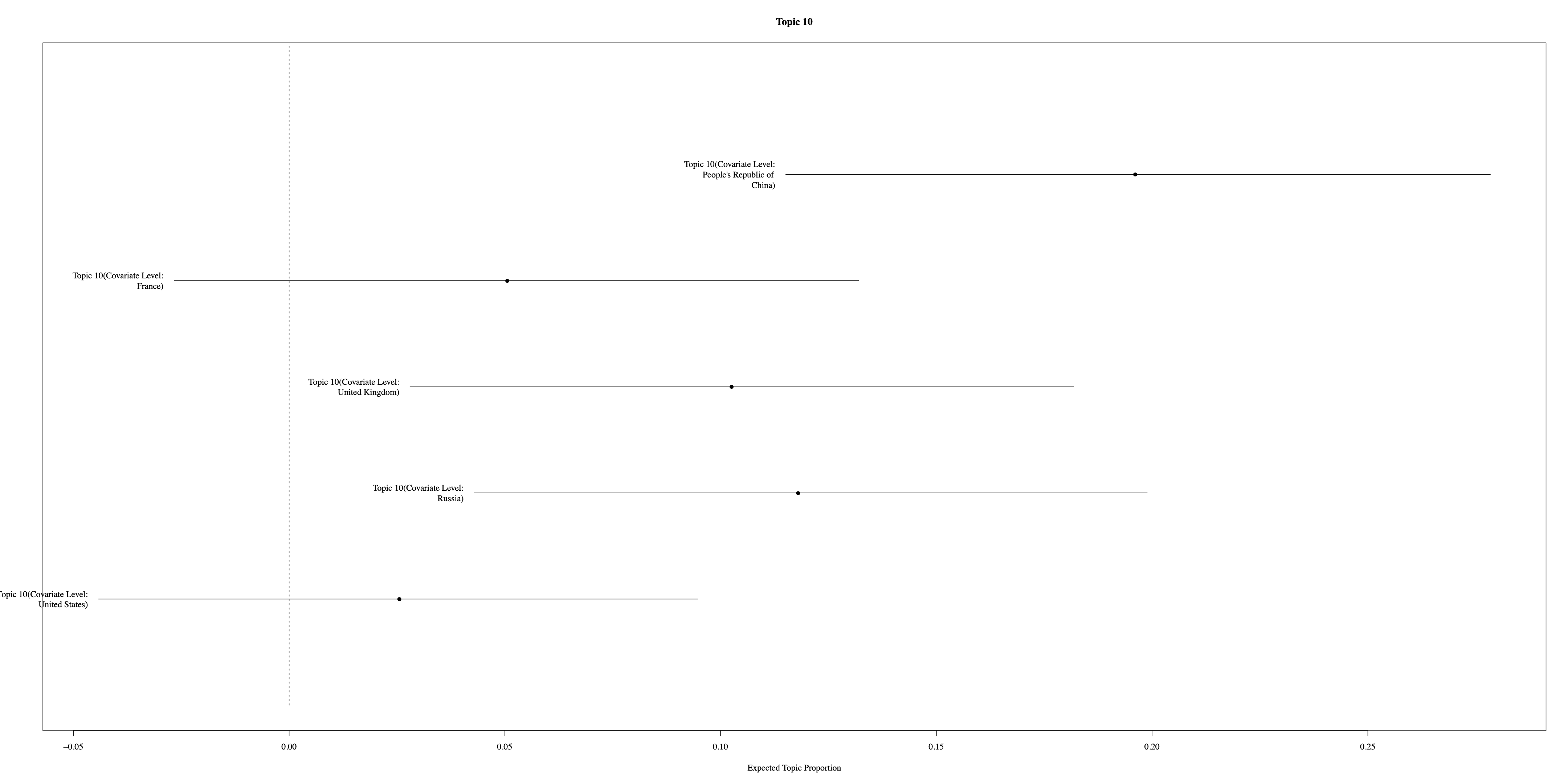
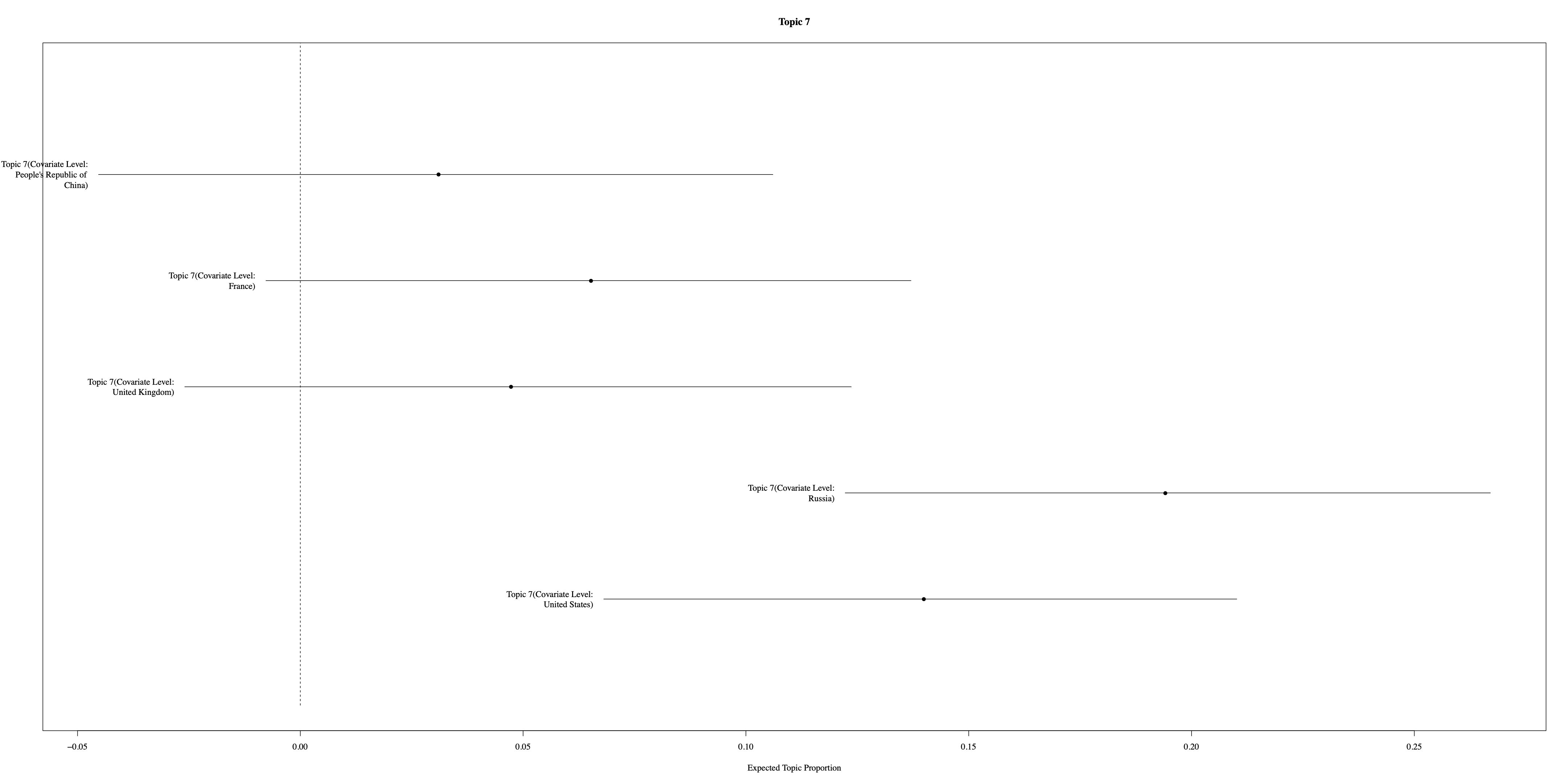
Additionally, Figure 6 illustrates the distribution of the first four topics across the P5 nations, highlighting variations in topic emphasis among these key players in international diplomacy. Notably, the Russian Federation and the United States exhibit distinct patterns of emphasis on topics related to the Cold War and millennium development goals, respectively.
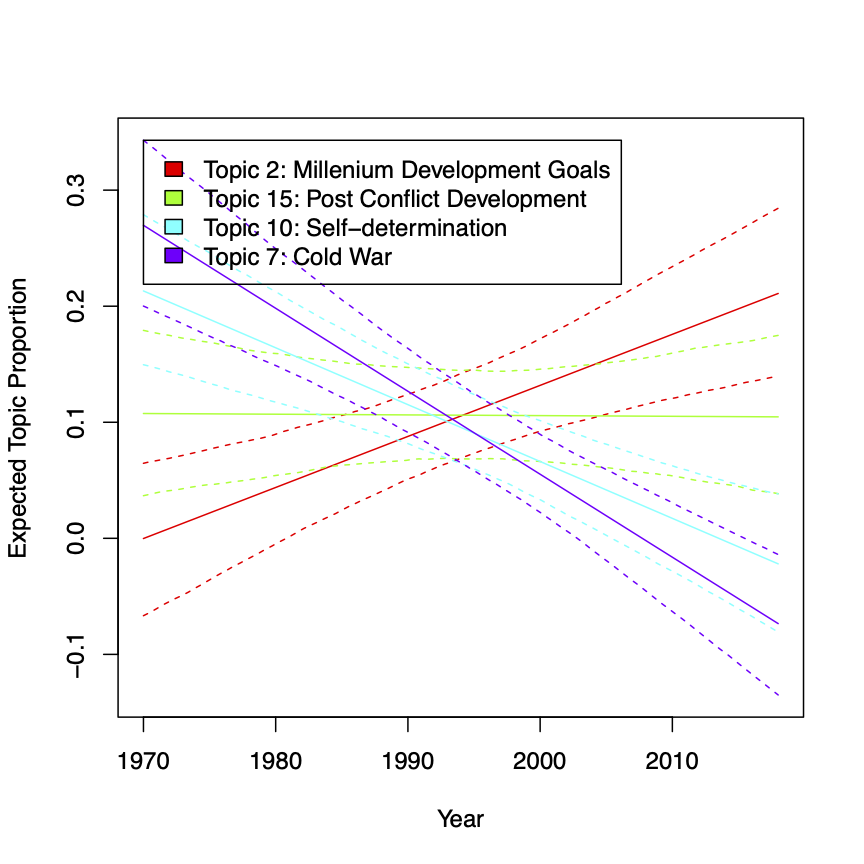
Figure 7 presents the top four discussed topics over the years, indicating evolving priorities in the discourse among the P5 nations. While topics related to the Cold War show a decline, discussions on millennium development goals and post-conflict development witness increasing attention, reflecting shifting global dynamics and priorities.
Classifying Speeches based on Choice of Words
I developed a classification model using XGBoost in R to predict the country of origin based on the content of speeches, treating the choice of words as predictive features. The outcome variable is a multinomial categorical variable representing five countries: the United States (0), the United Kingdom (1), France (2), China (3), and Russia (4). By employing the 'multi:softmax' objective for multinomial classification, the model learns to classify speeches into these five classes.
The model performed impressively well during both training and testing phases. Training on a dataset comprising 197 documents, the model demonstrated high accuracy, with only a few instances of misclassification. In the test set of 46 documents, the algorithm achieved an outstanding accuracy rate of 93.48%, with a narrow 95% confidence interval ranging from 82.21% to 98.63%.
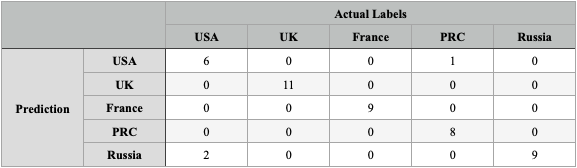
Table 2 provides a visualization of the model's performance, illustrating its ability to correctly classify the majority of documents with minimal errors. Notably, the algorithm exhibited only one misclassification in the test set, underscoring its robustness and reliability.
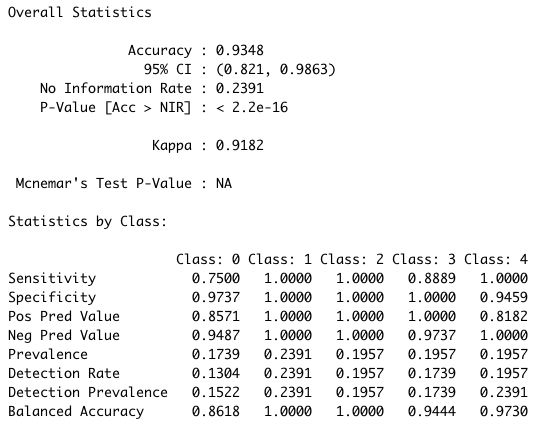
Moreover, Figure 8 presents comprehensive statistics summarizing the model's overall performance, including accuracy metrics and confidence intervals. These results reaffirm the effectiveness of the classification model in accurately predicting the country of origin based on speech content.
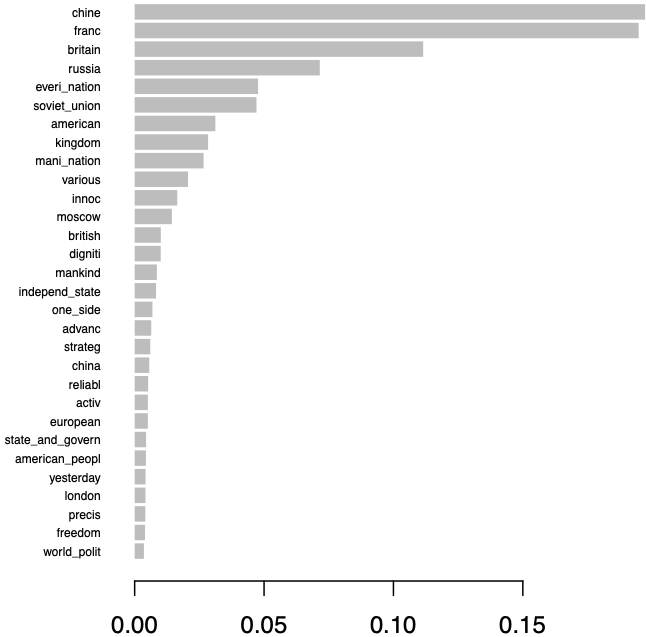
Finally, Figure 9 highlights the most important features used by the model to distinguish between documents, shedding light on the key words and phrases that contribute significantly to the classification process. This insight can further enhance our understanding of the linguistic characteristics that differentiate speeches from different countries.
Conclusion
In conclusion, this study provides valuable insights into the sentiment, topics, and linguistic characteristics of speeches made at the United Nations General Debate. Despite the challenges and limitations inherent in analyzing textual data, the techniques employed in this research have yielded promising results.
The analysis reveals an overall positive sentiment prevailing within the General Debate, reflecting a collaborative spirit among nations in addressing global challenges. This positive outlook bodes well for international cooperation and the pursuit of collective goals.
Furthermore, the structured topic modeling approach has identified key themes discussed at the General Debate, shedding light on the priorities and concerns of member nations. Variations in topic prevalence among countries underscore the importance of understanding the unique perspectives and foreign policy priorities of different nations.
The classification model developed in this study demonstrates the potential of supervised learning techniques in predicting the country of origin based on speech content. The high accuracy achieved by the model suggests that the choice of words in speeches may indeed be influenced by the country, opening avenues for further investigation into the data generation process.
Moving forward, future research could delve deeper into understanding the underlying factors driving sentiment and topic prevalence in General Debate speeches. Additionally, exploring the relationship between speech content and foreign policy objectives could provide valuable insights into the diplomatic strategies of member nations.
Overall, this study contributes to the growing body of literature on text analysis in international relations and offers a framework for leveraging computational techniques to analyze diplomatic discourse at the United Nations.
Bibliography
- Baturo, A., & Dasandi, N. (2017). What drives the international development agenda? An NLP analysis of the united nations general debate 1970–2016. 2017 International Conference on the Frontiers and Advances in Data Science (FADS), 171–176. https://doi.org/10.1109/FADS.2017.8253221
- Charter of the United Nations. (2015, August 10). https://www.un.org/en/charter-united-nations/index.html
- General Assembly of the United Nations. (n.d.). United Nations. Retrieved February 11, 2021, from https://www.un.org/en/ga/about/ropga/sessions.shtml
- Jankin Mikhaylov, S., Baturo, A., & Dasandi, N. (2019). United Nations General Debate Corpus [Data set]. Harvard Dataverse. https://doi.org/10.7910/DVN/0TJX8Y
- Lexicoder Sentiment Dictionary (2015)—Data_dictionary_LSD2015. (n.d.). Retrieved May 15, 2021, from https://quanteda.io/reference/data_dictionary_LSD2015.html
- lexicon package—RDocumentation. (n.d.). Retrieved May 15, 2021, from https://www.rdocumentation.org/packages/lexicon/versions/1.2.1
- Monroe, B. L., Colaresi, M. P., & Quinn, K. M. (2008). Fightin’ Words: Lexical Feature Selection and Evaluation for Identifying the Content of Political Conflict. Political Analysis, 16(4), 372–403. https://doi.org/10.1093/pan/mpn018
- Quinn, K. M., Monroe, B. L., Colaresi, M., Crespin, M. H., & Radev, D. R. (2010). How to Analyze Political Attention with Minimal Assumptions and Costs. American Journal of Political Science, 54(1), 209–228. https://doi.org/10.1111/j.1540-5907.2009.00427.x
- UN General Assembly begins annual high-level debate. (2001, November 10). UN News. https://news.un.org/en/story/2001/11/20112-un-general-assembly-begins-annual-high-level-debate
- Young, L., & Soroka, S. (2012). Affective News: The Automated Coding of Sentiment in Political Texts. Political Communication, 29(2), 205–231. https://doi.org/10.1080/10584609.2012.671234